Sous le capot de l’API de floutage de Panoramax
Le floutage des images prises dans l’espace public est un passage obligé avant leur publication.
C’est un sujet important pour le projet Panoramax, délicat aussi pour trouver un équilibre entre respect de la vie privée et utilisation des images.
Voici résumé les différentes étapes qui ont permis de mettre en place l’API de floutage utilisée au démarrage du projet.
Détecter les zones à flouter
Lors des premiers essais de floutage, ce sont des algorithmes de segmentation qui ont été utilisés. Ils déterminent pour chaque pixel composant une image à quelle classe d’objet celui-ci est le plus probable d’appartenir.
Exemple de masque issu de segmentation:

Floutage par segmentation sémantique:

Bien sûr les classes d’objets dépendent des données qui ont été utilisées pour entraîner le modèle de segmentation. Chaque image d’entraînement a donc été annotées et délimitant les zones correspondantes aux personnes, véhicules, arbres, bâtiments, etc.
Annoter ce type d’images prends beaucoup de temps, on utilise donc souvent des modèles déjà entraînés ou des données déjà annotées.
Pour notre cas (les vues de rues), des modèles existent mais ont été entraînés sur des images pas forcément ressemblantes au contexte français et qui ont le plus souvent été prises en milieu urbain.
Un autre défaut de la segmentation, c’est la façon d’appliquer le floutage dans l’image d’origine, qui nécessite le plus souvent un traitement global et donc une décompression/recompression de l’image complète avec les pertes associées car les zones à flouter peuvent avoir des formes complexes (polygones).
De la segmentation à la détection d’objets
L’autre technique est la détection d’objets. Pour chaque objet détecté, une zone rectangulaire englobante est retournée avec la classe de l’objet détecté et le taux de confiance.
On peut ici appliquer ensuite un “floutage différentiel” décrit ci-dessous en minimisant les pertes de qualité.
L’annotation est aussi beaucoup plus facile, il suffit de sélectionner un rectangle englobant l’objet dans l’image d’entraînement et d’indiquer de quelle classe il s’agit ce qui se fait relativement vite.
Annoter collaborativement
L’entraînement d’un modèle d’IA repose sur les recettes habituelles en matière de pédagogie: répétition et exemples.
Il faut donc annoter un nombre suffisant d’images pour entraîner correctement le modèle. Dans notre cas c’est un millier de photos qui ont été utilisées, une partie est conservée pour vérifier l’entraînement (la validation). Sur chaque photos ont été repéré à l’aide d’un rectangle les visages, plaques d’immatriculation et panneaux de signalisation (on verra pourquoi cette troisième catégorie).
Travail répétitif, ingrat, un peu long, mais si on le partage c’est nettement plus confortable. C’est ce que l’on a fait en utilisant le logiciel “Label Studio” qui permet de faire une annotation collaborative, donc à plusieurs. En quelques jours c’était fait !

Faux négatifs et faux positifs
Les algorithmes de détection ne sont pas parfaits et on a donc une zone grise où l’on n’est pas sûr de la détection.
Pour chaque détection, les algorithmes donnent un taux de confiance et si l’on ne prend en compte qu’ un taux élevé de confiance, on risque de passer à côté de certaines détections (les faux négatifs).
A l’inverse, si l’on baisse trop le taux de confiance, on va bien diminuer les faux négatifs, mais on va augmenter les faux positifs. On a pris pour un visage ou une plaque d’immatriculation quelque chose d’autre.
Si l’on floute définitivement ces zones dans l’image d’origine qu’on ne conserve pas, on perd définitivement la zone floutée
Le floutage différentiel
L’idée d’un “floutage différentiel” est née pour compenser ces imperfections, voici l’idée générale :
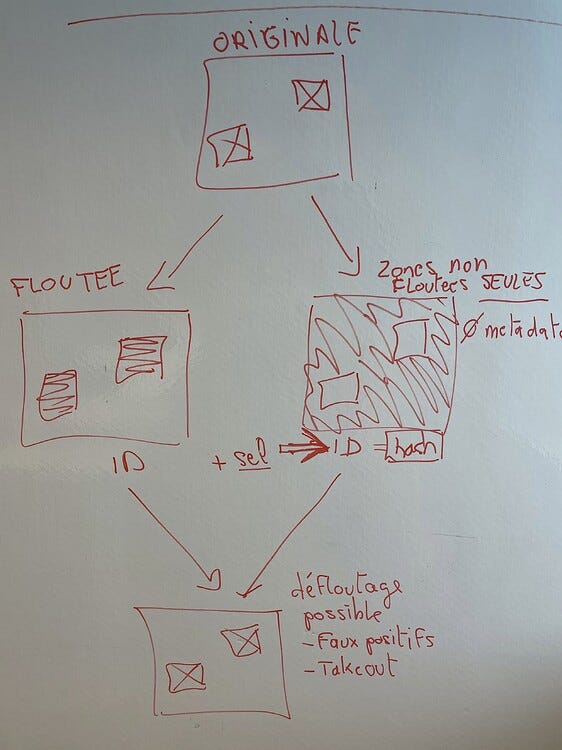
Dans cet exemple, on a détecté deux zones dans l’image originale:
- on va extraire ces deux zones, et uniquement elles du reste de l’image
- on applique un floutage dessus
- on réintègre ces zones floutées à l’originale que l’on ne conserve pas
Si l’on veut pouvoir “déflouter” un faux positif, on peut conserver la zone en question, sans le reste de l’image et sans le contexte (metadonnées).
Le nom du fichier conservé peut être généré par une formule de hachage cryptographique, qui ne permettra pas de remonter à l’image d’origine. On conserve ainsi, un visage ou une plaque mais sans aucun contexte, ce qui est une forme d’anonymisation.
Limiter les pertes de qualité d’image
Ces traitements modifiant une image à la base compressée en format JPEG génèrent des petites pertes de qualité car elles nécessitent une décompression et une recompression qui à chaque fois introduisent une perte de qualité.
C’est là où il faut descendre à un niveau un peu plus bas et comprendre comment les images JPEG sont compressées, car nous ne voulons modifier que de petites parties de l’image (les zones à flouter) et pas l’image entière.
Il se trouve que l’algorithme de compression JPEG n’agit pas sur l’image dans sa globalité mais découpe les images en petits blocs tels que ceci :

Chaque bloc (appelé “MCU”) est compressé de façon indépendante des autres. L’image JPEG est de plus séparées en plusieurs couches, une de luminance (Y) et deux de chrominance (Cr et Cb) et pour améliorer la compression les couches de chrominance sont “sous-échantillonnées”, c’est à dire qu’on prend les valeur moyennes d’un pixel sur deux, voir un pixel sur 4.
Les MCU de luminance font 8x8 pixels, ceux de chrominances peuvent aller de 8x8 à 16x16 pixels (voir http://blog.chinaunix.net/uid-20451980-id-1945150.html).
Il est donc possible de modifier des portions d’images JPEG en remplaçant juste les MCU (blocs de 8x8 à 16x16 pixels) couvrant les zones à flouter et donc sans toucher au reste de l’image. La perte de qualité se limite aux zones à flouter et leur environ proche.
Le outil proposé autour de la librairie JPEG (son petit nom est jpegtran) permettent de faire assez facilement ces manipulations, comme extraire une portion d’image (crop) ou remplacer une portion d’un image par une autre (drop) ou la remplacer par un aplat gris.
Quel niveau de floutage ?
Lors du partage des premiers essais de floutage, plusieurs personnes ont fait remarquer que le floutage ne semblait pas suffisant.
Il faut en effet adapter le niveau de floutage à la taille de la zone concernée. Un visage au loin sera définit par un bien plus petit nombre de pixels qu’un visage plus proche. Il faut donc que le niveau de flou soit proportionnel au nombre de pixels à flouter.
Le plus simple est de pixeliser la zone à flouter, c’est à dire la réduire à un nombre limité de pixels, puis à l’étendre à nouveau à la taille d’origine.
Après quelques recherches en ligne, les algorithmes de reconnaissance faciales semblent actuellement capables de fonctionner avec des visages définis par seulement 24 pixels de côté, ou 12 pixels entre les yeux.
C’est donc une pixellisation complète de la zone (visage complet) à 12 pixels de côté qui a été faite, avec ensuite un flou appliqué pour limiter l’effet visuel et une meilleure intégration dans l’image.
